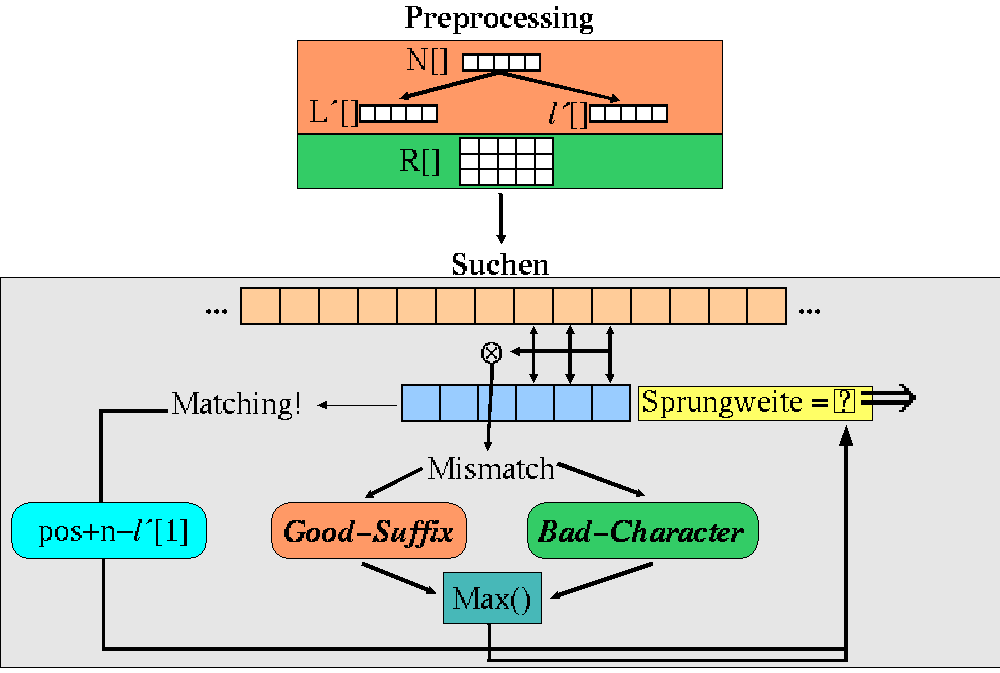
Der Boyer-Moore Algorithmus läuft in zwei Stufen ab. Zuerst wird das Preprocessing für die "Bad-Character-Rule" (grün) und - mit Hilfe der N-Boxes - für die "Good-Suffix-Rule" (orange) durchgeführt. Dann beginnt der eigentliche Suchvorgang. Auffallend hierbei ist, daß das Suchmuster (blau) immer von links nach rechts gescannt wird.
Tritt während des Vergleichens ein Mismatch auf, so wird sowohl mit der "Bad-Character-" als auch mit der "Good-Suffix-Rule" berechnet, wie weit das Suchmuster nach rechts springen darf. Das Maximum von beiden wird dann für den Sprung genommen.
Wird ein Vorkommen des Suchmusters im Text entdeckt, dann springt das Suchmuster um den Betrag "pos + n - l´[1]" nach rechts.
Im Folgenden werden die erwähnten Preprocessing Algorithmen für die "Bad-Character-" und die "Good-Suffix-Rule" erklärt.
Der original Boyer-Moore Algorithmus verwendet ein etwas anderes Preprocessing, das allerdings sehr schwer zu verstehen ist. Das hier vorgestellte Preprocessing ermöglicht dem Algorithmus jedoch ebenfalls eine Laufzeit, die in der Regel sogar unter O(n + m) liegt. Der Beweis für diese Laufzeit ist allerdings sehr komplex und ebenfalls schwer zu verstehen, weswegen hier darauf verzichtet wird.
| Vorherige Folie | Zurück zum Index | Nächste Folie |