|
|
|
|
|
|
Das Proseminar findet in zwei Gruppen [A] und [B] statt.
Der Termin für Gruppe [A] ist dienstags von 14:15 Uhr bis 15:15 Uhr im
Raum S2229,
der für Gruppe [B] ist dienstags von 15:30 Uhr bis 16:30 Uhr im
Raum S2229.
Hinweis: Die Teilnehmer werden gebeten, sich mit ihren
Betreuern in Verbindung zu setzen.
| 1. Mai: | Maifeiertag |
| 8. Mai: |
Cornelia Donner [A] Carolina Giobbi [B] Thema: Basic Concepts of Molecular Biology Betreuer: Michal Mnuk |
| 15. Mai: |
Hüsnü Güney Vortrag verschoben auf den 24.7., bitte
Session [B] besuchen Jannis Utz [B] Thema: Pairwise Sequence Alignment Betreuer: Thomas Schickinger |
| 22. Mai: |
[A] Vortrag entfällt, bitte Session [B] besuchen; Olivia Prazeres da Costa [B] Thema: Multiple Sequence Alignment Betreuer: Stefanie Gerke |
| 29. Mai: |
[A] Vortrag entfällt, bitte Session [B] besuchen; Christoph Taucher [B] Biological Data Bases Betreuer: Jens Ernst |
| 5. Juni: | Pfingstferien |
| 12. Juni: |
Cornel Babel [A] Melike Elmas [B] Thema: Fragment Assembly Betreuer: Klaus Holzapfel |
| 19. Juni: |
Emanuel Seidinger [A] Marc Offman [B] Thema: Physical Mapping Betreuer: Mark Scharbrodt |
| 26. Juni: |
Charlotte Junkers [A] Hermann Klann [B] Thema: Evolutionary Trees: Reconstruction from Character Data Betreuer: Ulrich Rührmair |
| 3. Juli: |
Simon Popp [A] Barbara Murner [B] Thema: Evolutionary Trees: Reconstruction from Distance Matrices Betreuer: Thomas Bayer |
| 10. Juli: |
Franz Strasser [A] Martin Leidenfrost [B] Thema: Genome Rearrangements Betreuer: Hanjo Täubig |
| 17. Juli: |
Susanne Klingelhöffer [A] Thema: Structure Prediction Betreuer: Ingo Rohloff |
| 24. Juli: |
Hüsnü Güney [A] Pairwise Sequence Alignment
Betreuer: Thomas Schickinger Andreas Unterweger [B] Structure Prediction Betreuer: Ingo Rohloff |
Nicht zuletzt durch die Datenflut des Human Genome Projects findet in der Biologie momentan ein Paradigmenwechsel statt. Die bei der Genomsequenzierung anfallenden Daten sind so umfangreich, daß bei ihrer Verarbeitung die Methoden der Informatik unerläßlich sind. Aus dieser Notwendigkeit heraus hat sich ein neues und aufregendes Fachgebiet entwickelt: die Bioinformatik. Dabei beschäftigt man sich zum einen mit Algorithmen die zur Strukturaufklärung von DNS-Strängen (der sogenannten Sequenzierung) aus den biotechnisch gewonnenen Daten beitragen, und zum anderen mit Algorithmen, die die Interpretation der gewonnenen Daten unterstützen. Damit ist die Bioinformatik eine der sich am schnellsten entwickelnden und wichtigsten interdisziplinären Anwendungen der Informatik überhaupt. Zu den folgenden Bereichen sollen im Hauptseminar die aktuellen Forschungsergebnisse im Bereich der Algorithmik vorgestellt werden:
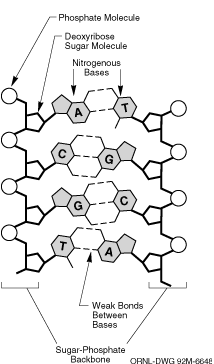 Das Sequence Alignment ist eines der fundamentalsten und ältesten
Probleme der Bioinformatik.
Hierbei soll für zwei gegebenen Zeichenreihen (interpretiert als
Abfolge von Nuklein- oder Aminosäuren) festgestellt werden, ob
sie ähnlich sind, und wenn ja, wie sie mit einer minimalen Anzahl
elementarer Operationen (Löschen, Einfügen, Substitution von
Zeichen) ineinander überführt werden können.
Werden zum Beispiel mehrere gleichen DNS-Sequenzen bzw. Proteine
sequenziert, so will man hiermit feststellen, ob bzw. inwieweit die
Ergebnisse dieselben sind.
Ein anderes Beispiel (in dem man eine Sequenz mit vielen anderen
vergleicht) ist die Suche in einer DNS- bzw. Protein-Datenbank, wobei
man feststellen möchte, ob die neue Sequenz schon bekannt ist
oder nicht.
Das Sequence Alignment ist eines der fundamentalsten und ältesten
Probleme der Bioinformatik.
Hierbei soll für zwei gegebenen Zeichenreihen (interpretiert als
Abfolge von Nuklein- oder Aminosäuren) festgestellt werden, ob
sie ähnlich sind, und wenn ja, wie sie mit einer minimalen Anzahl
elementarer Operationen (Löschen, Einfügen, Substitution von
Zeichen) ineinander überführt werden können.
Werden zum Beispiel mehrere gleichen DNS-Sequenzen bzw. Proteine
sequenziert, so will man hiermit feststellen, ob bzw. inwieweit die
Ergebnisse dieselben sind.
Ein anderes Beispiel (in dem man eine Sequenz mit vielen anderen
vergleicht) ist die Suche in einer DNS- bzw. Protein-Datenbank, wobei
man feststellen möchte, ob die neue Sequenz schon bekannt ist
oder nicht.
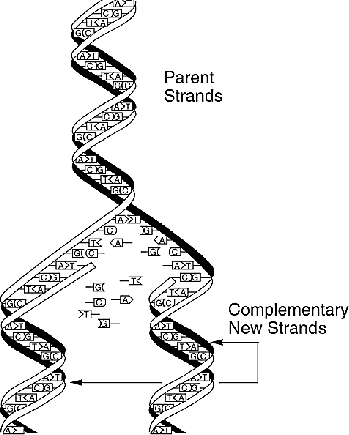 Aus biotechnologischen Gründen können immer nur relativ
kurze Stücke eines DNS-Strangs sequenziert werden.
Für eine vollständige Strukturauflösung eines langen
DNS-Strangs muß dieser also in viele kurze aufgeteilt werden,
wobei in Wirklichkeit die Bruchstücke vieler identischer Kopien
dieses DNS-Strangs betrachtet werden.
Beim Fragment Assembly will man nun aus dieses Teilsequenzen wieder
die gesamte Sequenz des langen DNS-Strangs rekonstruieren.
Aus biotechnologischen Gründen können immer nur relativ
kurze Stücke eines DNS-Strangs sequenziert werden.
Für eine vollständige Strukturauflösung eines langen
DNS-Strangs muß dieser also in viele kurze aufgeteilt werden,
wobei in Wirklichkeit die Bruchstücke vieler identischer Kopien
dieses DNS-Strangs betrachtet werden.
Beim Fragment Assembly will man nun aus dieses Teilsequenzen wieder
die gesamte Sequenz des langen DNS-Strangs rekonstruieren.
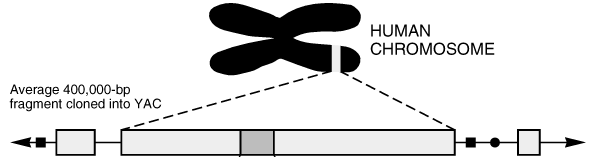 Hat man Bereiche von DNS-Strängen eines Chromosoms sequenziert,
so will man natürlich auch wissen, wo in diesem Chromosom ein
sequenzierter Teil vorkommt.
Biotechnisch können dabei bestimmte sehr kurze Teile des
Chromosoms markiert werden.
Diese Markierungen kann man auf den Bruchstücken des DNS-Strangs
wiederfinden.
Ziel ist es nun, die Bruchstücke so zusammenzusetzen, daß
die markierten Stellen auf dieser Zusammensetzung an denselben Stellen
sind wie im ursprünglichen Chromosom.
Hat man Bereiche von DNS-Strängen eines Chromosoms sequenziert,
so will man natürlich auch wissen, wo in diesem Chromosom ein
sequenzierter Teil vorkommt.
Biotechnisch können dabei bestimmte sehr kurze Teile des
Chromosoms markiert werden.
Diese Markierungen kann man auf den Bruchstücken des DNS-Strangs
wiederfinden.
Ziel ist es nun, die Bruchstücke so zusammenzusetzen, daß
die markierten Stellen auf dieser Zusammensetzung an denselben Stellen
sind wie im ursprünglichen Chromosom.
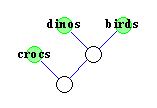 Durch die Evolution haben sich die verschiedenen Spezies aus
gemeinsamen Vorfahren weiterentwickelt, die zum Teil schon lange
wieder ausgestorben sind.
Mit Hilfe eines phylogenetischen Baumes will man nun den Stammbaum
verschiedener Spezies rekonstruieren, wobei man nur die noch lebenden
Spezies kennt.
Diese lebenden Spezies bilden nun die Blätter des
phylogenetischen Baumes.
Durch die Evolution haben sich die verschiedenen Spezies aus
gemeinsamen Vorfahren weiterentwickelt, die zum Teil schon lange
wieder ausgestorben sind.
Mit Hilfe eines phylogenetischen Baumes will man nun den Stammbaum
verschiedener Spezies rekonstruieren, wobei man nur die noch lebenden
Spezies kennt.
Diese lebenden Spezies bilden nun die Blätter des
phylogenetischen Baumes.
 Ziel ist nun, die inneren Knoten des Baumes so zu konstruieren,
daß stark verwandte Spezies im Baum nah zusammen (durch einen
kürzeren Pfad verbunden) sind.
Zur Konstruktion phylogenetischer Bäume werden dabei
unterschiedliche Methoden zur Bestimmung des Verwandtschaftsgrades
verwendet.
Ziel ist nun, die inneren Knoten des Baumes so zu konstruieren,
daß stark verwandte Spezies im Baum nah zusammen (durch einen
kürzeren Pfad verbunden) sind.
Zur Konstruktion phylogenetischer Bäume werden dabei
unterschiedliche Methoden zur Bestimmung des Verwandtschaftsgrades
verwendet.
 Vergleicht man das gesamte Genom von verschiedenen Spezies, so
hätte man gerne einen Abstandsbegriff, der für ein Paar von
Spezies aussagt, wie verwandt sie miteinander sind.
Bei vielen Spezies unterscheiden sich das Erbgut oft nur durch eine
andere Anordnung der Gene innerhalb des Erbguts.
Daher definiert man den Abstandsbegriff durch die minimale Anzahl an
gewissen Elementaroperationen, die nötig sind, um die Genome der
Spezies ineinander zu überführen.
Dabei sind hier die elementaren Operationen (im Gegensatz zum Sequence
Alignment) globale Operationen.
Am häufigsten treten sogenannte Inversionen und Transpositionen
auf, bei denen entweder ein ganzer Abschnitt der DNS-Strangs umgedreht
wird oder zwei lange benachbarte Abschnitte miteinander vertauscht
werden.
Vergleicht man das gesamte Genom von verschiedenen Spezies, so
hätte man gerne einen Abstandsbegriff, der für ein Paar von
Spezies aussagt, wie verwandt sie miteinander sind.
Bei vielen Spezies unterscheiden sich das Erbgut oft nur durch eine
andere Anordnung der Gene innerhalb des Erbguts.
Daher definiert man den Abstandsbegriff durch die minimale Anzahl an
gewissen Elementaroperationen, die nötig sind, um die Genome der
Spezies ineinander zu überführen.
Dabei sind hier die elementaren Operationen (im Gegensatz zum Sequence
Alignment) globale Operationen.
Am häufigsten treten sogenannte Inversionen und Transpositionen
auf, bei denen entweder ein ganzer Abschnitt der DNS-Strangs umgedreht
wird oder zwei lange benachbarte Abschnitte miteinander vertauscht
werden.
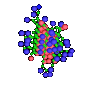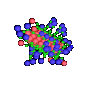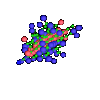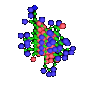 Die Funktionalität eines Proteins wird im wesentlichen durch
seine räumliche Struktur bestimmt.
Leider sind physikalische Strukturaufklärungsverfahren im
Vergleich zur biologischen Sequenzierung sehr aufwendig.
Deshalb ist man an Algorithmen interessiert, die aus der
Aminosäuresequenz eines Proteins die räumliche Struktur des
Proteins vorhersagen oder die zu einer gegebenen räumlichen
Struktur eine geeignete Aminosäuresequenz angeben, die sich in
die vorgegebene Struktur faltet.
Die Funktionalität eines Proteins wird im wesentlichen durch
seine räumliche Struktur bestimmt.
Leider sind physikalische Strukturaufklärungsverfahren im
Vergleich zur biologischen Sequenzierung sehr aufwendig.
Deshalb ist man an Algorithmen interessiert, die aus der
Aminosäuresequenz eines Proteins die räumliche Struktur des
Proteins vorhersagen oder die zu einer gegebenen räumlichen
Struktur eine geeignete Aminosäuresequenz angeben, die sich in
die vorgegebene Struktur faltet.
Als Grundlage für dieses Proseminar dient hauptsächlich das erste Buch der folgenden Liste:
Es gibt auch eine detaillierte Themenliste mit Literaturangaben.
|
|
Merkblatt zur Gestaltung eines Seminarvortrags. (Die Tips auf diesem Merkblatt sind keine offiziellen Anforderungen oder Bewertungskriterien der TU München, sondern aus der Praxis eines Seminarleiters heraus entstandene Ratschläge.) |
|
|
Tips zur Erstellung von Folien mit LaTeX (einschließlich Rahmen-Datei als Vorlage) |
Weitere Auskünfte erteilen Jens Ernst und Volker Heun.