 |
TU München,
Institut für Informatik
Lehrstuhl für Effiziente Algorithmen
|

|
Stand der Forschung und eigene Vorarbeiten
- Stand der Forschung
- Große reale Netzwerke
- Darstellung von Graphdaten
- Algorithmische Aspekte
- Eigene Vorarbeiten
- Entwicklung von Visualisierungstechniken
- Erste Schritte bezüglich interessanter Fragestellungen
Stand der Forschung
Die Visualisierung von vernetzten Datensätzen in Form von Graphen ist ein
häufig eingesetztes Mittel, um Eigenschaften und Zusammenhänge der Daten
zu analysieren und aufzuzeigen. Die Grundlagen für derartige Untersuchungen liegen
einerseits in der Information über die darzustellenden Netzwerke und andererseits in
der Techniken, die eine sinnvolle graphische Repräsentation der Netzwerke
ermöglichen.
In beiden Bereichen wurden gerade auch für große Netzwerke bereits viele
Analysen, Techniken und Algorithmen entwickelt, die im Folgenden kurz vorgestellt
werden sollen. Die Begriffe Netzwerke und Graphen werden dabei weitestgehend synonym
verwendet.
Große reale Netzwerke
Bei der Visualisierung großer realer Netzwerke können die Graphen in zwei
Gruppen aufgeteilt werden: Einerseits in Graphen, die eine
bekannte Struktur eines Netzwerks widerspiegeln. Andererseits sind häufig
Netzwerke zu visualisieren, über die keine genauen strukturellen Aussagen vorliegen,
wie z.B. das soziale Gefüge in einer Bevölkerungsgruppe oder Referenzen im Internet.
Gerade wegen dieser Beispiele sind die Netzwerke des zweiten Typs bis heute
Bestandteil zahlreicher wissenschaftlicher Untersuchungen.
Netzwerke mit bekannter Struktur
Netzwerkdaten aus diesem Bereich dienen der Beschreibung funktioneller Strukturen, wie
beispielsweise (bio)chemischer Prozesse. So kann der aus der Chemie bekannte
Zitronesäurezyklus so durch ein Netzwerk dargestellt werden, dass einzelne
Ablaufphasen oder funktionelle Einheiten als Komponenten bzw. Teilgraphen
repräsentiert werden. Diese Einheiten können ihrerseits auch wieder unterteilt
sein. Auf diese Art und Weise können die Abläufe derart verfeinert werden,
dass abschließend ein Netzwerk entsteht, aus dem
sowohl die Informationen über die wesentlichen Teilgruppen als auch Details
auf der Molekülebene in den involvierten chemischen Reaktionen abgelesen werden
können. Die Zusammenhänge im Bereich der Genanalyse und Evolutionstheorie sind
andere Beispiele für solche Graphen.
Ferner kann man auf Netzwerke betrachten, die
gewissen logischen Strukturen genügen und entsprechend aufgebaut sind. Ein
typischer Vertreter dieser Modelle ist die Baumstruktur, wie sie in Organigrammen
oder auch in Entscheidungsmodellen vorkommt. Aber auch andere, zum Teil geometrische
Einheiten wie Kreise oder Sterne kommen häufig zum Einsatz. Speziell im Bereich
der Rechnernetze und Schaltkreise werden diese Modelle als Bausteine zur
Konstruktion komplexer Gesamtgebilde verwendet.
Für diese Arten von Netzwerken ist eine Zerteilung für
eine hierarchische Darstellung bereits durch den Aufbau
vorgeben. Für diese stellt sich daher hauptsächlich die
Frage nach einer übersichtlichen Darstellung.
Netzwerke mit unbekannten Strukturen
Für Netzwerke, über die man keine genauen strukturellen Informationen besitzt,
gibt es zahlreiche alltägliche Beispiele, wie Zugverbindungen
innerhalb eines nationalen Eisenbahnnetzes, Darstellungen von
Bekanntschaftsverhältnissen zwischen Personen, etwa Vorgesetztenverhältnisse oder
der sogenannte Hollywood-Graph (welcher Schauspieler hat bereits mit welchem
in einem gemeinsamen Film gespielt). Eine in letzter Zeit immer häufiger untersuchte
Gruppe von Graphen ist die aus dem Bereich des World Wide Web. Hier wurden
besonders die physikalischen Netzwerke sowie der Referenz-Graph untersucht.
Konzept der Small World Graphen
Um allgemeine Aussagen über die Graphen machen zu können, wurde versucht,
Modelle zu definieren, die grundlegende Eigenschaften
dieser Graphen zusammenfassen.
Für eine große Menge von Netzwerken, darunter auch die oben genannten, wurde der
Begriff der Small World Graphen geprägt [Wat99].
Es handelt sich dabei um die Graphen, die die folgenden Eigenschaften besitzen:
- geringe Dichte - Obwohl ein Graph mit n Knoten bis zu n(n-1)/2 =
O(n2) Kanten besitzen kann, haben Small World Graphen nur sehr
wenig Kanten in der Größenordnung O(n) mit einem geringen konstanten
Faktor, der häufig kleiner 10 ist.
- geringer Durchmesser - Trotz der relativ kleinen Kantenzahl ist der
Durchmesser der Graphen (die größte Anzahl der Kanten, die
mindestens durchlaufen werden müssen, um zwei beliebige Knoten zu
verbinden) gering und wächst nur unmerklich mit der Anzahl der
Knoten (z.B. O(log n)).
- Clusterbildung - Small World Graphen neigen dazu, Cluster auszubilden.
D.h. wenn zwei Knoten miteinander verbunden sind, dann ist es sehr
wahrscheinlich, dass große Teile ihrer Nachbarschaft oder Knoten mit
geringen Abstand gleich sind.
In der Vergangenheit wurden diese Eigenschaften für die oben genannten
Netzwerke nachgewiesen. Für die ungerichteten Graphen konnte dies
problemlos geschehen [Ada99, AJB99], für
gerichtete Netzwerke hingegen müssen einige Definitionen weiter gefasst werden.
Nachdem die Gruppe der Small World Graphen eine adäquate Beschreibung
für die betrachtenten Netzwerke zu sein scheint, wurden auch viele
Anläufe unternommen, Modelle zu entwickeln, die den Anforderungen der
Small World Graphen genügen. Im Folgenden sind einige ungerichtete
Modelle für Small World Graphen aufgelistet:
-
Watts und Strogatz [WS98] - In
diesem Modell sind alle Knoten in einem Ring angeordnet, wobei jeder
Knoten mit seinen k linken und rechten Nachbarn durch eine Kante
verbunden ist. Dieser Graph wird so modifiziert, das jede Kante mit
kleiner Wahrscheinlichkeit durch eine zufällige für den
Graphen neue Kante ersetzt wird (Gleichverteilung bei der Wahl einer
neuen Kante).
-
Kleinberg [Kle00] - Diese Modell
basiert auf einem Gitter, wobei jeder Knoten durch sogenannte lokale
Kontakte mit den Knoten verbunden ist, zu denen er eine Gitterdistanz
kleiner gleich k besitzt. Ferner hat jeder Knoten noch q long-range
Kontakte zu verbleibenden Knoten wobei die Kantenwahrscheinlichkeit
für die zwei Knoten mit der Entfernung d gerade d-r
ist.
-
Albert und Barabasi [BAH99] - Dies
ist ein Modell, bei dem nicht eine feste Grundstruktur modifiziert
wird, sondern in dem nur die Knotengrade gewissen Eigenschaften
genügen müssen. Für ein festes γ und A muss
gelten, dass die Wahrscheinlichkeit eines Knotengrades k proportional
zu Ak-γ ist. Dies ist auch Grund für die
Bezeichnungen exponential degree sequence und
power-law, die häufig in Zusammenhang mit diesem Graphen
verwendet wird.
Durchgeführte Analysen für die Referenzstruktur des WWW
Gerade für das die Referenzstruktur im WWW wurden zahlreiche Untersuchungen
durchgeführt. Den Untersuchungen wurden hierbei zwei verschiedene Datenmodelle
zugrunde gelegt. Neben dem ungerichteten Graphen, in dem eine Kante für eine
Referenz zwischen zwei Webseiten steht, wird gerade in den letzte Jahren immer
häufiger der kompliziertere gerichtete Fall untersucht.
Im Wesentlichen ergibt sich in beiden Fällen eine große
Zusammenhangskomponente, die ca. 90% der Knoten enthält.
Für den ungerichteten Fall hat diese die Struktur eines dichten Graphen,
der sich an seinen Rändern immer mehr verästelt.
Im gerichteten Fall, für den auch die Bezeichnung Web-Graph
geprägt wurde, ergaben jüngste Untersuchungen
[BKM+00], dass sich die
große Zusammenhangskomponente in vier ungefähr
gleichgroße Teile unterteilen lässt. Dies Komponenten
sind: eine starke Zusammenhangskomponente (SCC), eine Menge von
Knoten (IN) von denen aus die Menge SCC erreicht werden kann,
jedoch nicht umgekehrt, eine Menge von Knoten (OUT), die von der
Menge SCC erreichbar ist, jedoch wiederum nicht umgekehrt. Bei den
restlichen Knoten (Tendrils und Tubes) handelt es sich um die
Knoten, die die Menge SCC weder erreichen noch von dieser
erreichbar sind (siehe
Abbildung).
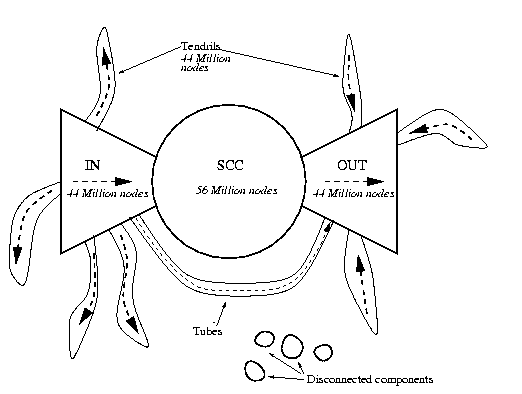 Web Graph für WWW Referenzen
[BKM+00]
Web Graph für WWW Referenzen
[BKM+00]
Sowohl für den gerichteten als auch den ungerichteten Fall wurden in zahlreichen
Analysen folgende Eigenschaften festgestellt:
- Durchmesser - Gerade für den ungerichteten Graphen ermittelten Albert, Jeong
und Barabasi [AJB99] einen relativ kleinen Durchmesser
von 19 Schritten. Für den gerichteten Fall muss
diese Angabe jedoch etwas relativiert werden. Wie aus obiger Abbildung ersichtlich ist,
kann nicht jede Webseite von jeder Webseite erreicht werden. D.h. der Begriff Durchmesser
kann nur auf die Knotenpaare angewendet werden, für die eine Verbindung existiert.
In [BKM+00] wird gezeigt, dass für die meisten Paare die Weglänge
sehr gering ist und im Durchschnitt den Wert 16 besitzt. D.h. die zweite Eigenschaft der
Small World Graphen ist somit weitestgehend erfüllt.
- Degree Sequence - Bei diesem Gütekriterium werden quantitativ die gleichen
Aussagen für den gerichteten und ungerichteten Fall erzielt. Der Grad (im
gerichteten Fall Eingangs-/Ausgangsgrad) eines Knotens ist nach dem bereits erwähnten
Prinzip der exponential degree sequence verteilt, was gerade dieses Modell für
weitere Untersuchungen interessant erscheinen lässt. Der konstante Exponent liegt
bei ungefähr -2.5.
- wichtige Knoten - Kleinberg hat in [Kle98] nachgewiesen, dass
es einige sogenannte good authorities gibt. Das sind Knoten, die verwendet werden
können, um gute Suchergebnisse bei der Suche im World Wide Web zu erzielen. Häufig
sind dies Seiten, mit einem großen Eingangs- bzw. Ausgangsgrad. In
[BKM+00] wird nachgewiesen, dass das Entfernen dieser Knoten jedoch
keinen wesentlichen Einfluss auf den Zusammenhang im Netz haben. Erst beim beim
Entfernen von Knoten mit Grad größer ca. 20 treten deutliche Zerteilungseffekte auf.
Zusammenfassung und weitere Fragestellungen
Die Untersuchungen belegen somit, dass
große reale Graphen, soweit sie nicht nach einem strukturellen Prinzip aufgebaut sind,
häufig in die Menge der Small World Graphen eingeordnet werden können.
Es sind erste Schritte unternommen worden, um strukturelle Eigenschaften der
Graphen sowie einige Modelle zu untersuchen. Gerade das power-law Modell scheint
speziell für das World Wide Web eine gute Beschreibung zu sein. Es wurden bereits
einige Algorithmen, z.B. für kürzeste Pfade oder Suche im WWW
[Kle00, BP98],
entwickelt, die auf derartigen Untersuchungen basieren.
Es bleibt jedoch anzumerken, dass noch viele Fragestellungen diesbezüglich
offen, oder nur unter zusätzlichen Annahmen über die Graphtopologie gelöst sind.
Darstellung von Graphdaten
Schon seit langem wird an Methoden und Heuristiken gearbeitet,
die eine gute Darstellung von Graphen auf dem Bildschirm ermöglichen.
Gerade in den letzten Jahren wurde neben reinen Darstellungstechniken
das Problem der Darstellung von großen Datenmengen, so beispielsweise von Graphen mit
einigen tausend Knoten relevant. Gängige Lösungsansätze für diese
Aufgabe werden abschließend zusammengefaßt.
Allgemeine Aspekte
Die bildliche Darstellung eines Graphen soll im wesentlichen dazu dienen,
Information über die Graphdaten möglichst übersichtlich und
kompakt zu repräsentieren. Dies beinhaltet neben dem reinen Zeichnen,
d.h. Anzeigen von Knoten und Kanten, auch eine sinnvolle Umsetzung von
weiteren Graphinformationen durch Beschriftung bzw. geeigneter
Visualisierung von Kanten/Knoten. Diese Zusatzinformationen müssen so
in die Darstellung eingearbeitet werden, dass sie zur weiteren
Informationsgewinnung herangezogen werden können.
Ferner sollen die Elemente des Graphen so angeordnet werden, dass
Abhängigkeiten von Komponenten oder Teilgraphen ersichtlich
sind. Hierzu zählen auch identische Darstellungsformen aller isomorpher
Subgraphen. Erst eine solche Darstellung ermöglicht es, die
zugrundeliegende Struktur eines Graphen schnell zu erfassen.
Um diese Ziele umzusetzen, kann man einige Methoden für eine gute
Darstellung formulieren. Hierunter fallen beispielsweise das
Kräftemodell, die Planarisierung von Graphen oder die
Orthogonaldarstellung. Neben diesen Anforderungen werden jedoch zumeist auch
ästhetische und strukturelle Ziele verfolgt, um dem Betrachter ein
möglichst übersichtliches Bild zu liefern
[DC98]. Einige dieser Ziele wie
Kreuzungsminimierung, sinnvolle Platzausnutzung oder gleichlange Kanten sind
bereits teilweise in den erwähnten Techniken integriert.
Es bleibt jedoch anzumerken, dass sich einige der Qualitätskriterien
widersprechen. In solchen Fällen sind je nach Zielsetzung der
Visualisierung die konkurrierenden Kriterien zu gewichten. Eine
ausführliche Beschreibung von gängigen Visualisierungstechniken
ist in [DETT98] zu finden.
Darstellung großer Graphen
Werden die zu zeichnenden Graphen groß, d.h. einige tausend Knoten und
mehr, so stößt man mit herkömmlichen Methoden schnell an die
Grenzen des Machbaren. Würde man alle Informationen darstellen, so
entstünde ein unüberblickbares und damit unbrauchbares Bild. Es
sind also neue Wege notwendig, um diese Datenflut zu bewältigen.
Ein erster Ansatz ist, die übliche 2-dimensionale Darstellung um eine
Dimension zu erweitern. Dies kann einen besseren Eindruck für den
Graphen liefern, wenn der Graph von verschiedenen Blickwinkeln betrachtet
werden kann. Man muss jedoch berücksichtigen, dass für eine
entsprechende Visualisierung meist wieder eine Projektion in die Ebene
nötig wird.
Eine andere Möglichkeit besteht in der Beschränkung auf einen so
Ausschnitt des Graphen, den man leicht darstellen kann. Diesen Ausschnitt
kann man dann über den Graphen wandern lassen, um so alle Teilbereiche
betrachten zu können. Diese Lösung ist problematisch, da eine
Gesamtansicht des Graphen fehlt. Durch sphärische Transformationen, mit
denen man am Rand des aktuellen Teilbereichs den restlichen Graphen verzerrt
darstellt, kann man dies umgehen. Dies Methode wird als
Fisheye-View bezeichnet.
Ein anderer Ansatz simuliert ein physikalisches Modell. D.h. wenn man einen
großen Graphen betrachten möchte, muss man dies aus ausreichender
Entfernung tun. In diesem Fall sieht man jedoch nicht alle Details sondern
nur einige Merkmale. Geht man näher an den Graphen heran, verschwinden
einige Bereiche aus dem Blickwinkel, dafür kommen mehr
Detail-Informationen zum Vorschein. Dies kommt einem Zoom auf den Graphen
gleich. Wichtig bei dieser Vorgehensweise ist die sogenannte mental
map. Darunter versteht man das Bild, das sich ein Betrachter vom
Graphen macht. Dieses Bild soll auch bei häufigen Betrachtungswechseln
stimmig bleiben. Wenn man auf einen Teilbereich zoomt und dann den Fokus
wieder vergrößert, soll sich wieder das gleiche Bild ergeben wie
vor dem Zoomen. Gleiches gilt beim Wandern über den Graphen.
Bei diesen Möglichkeiten mit großen Datenmengen zu arbeiten,
erkennt man schnell den wesentlichen Kern des Problems. Es ist nicht
möglich, alle Daten anzuzeigen, sondern man muss einen Graphen
repräsentieren, der einen "gewünschten" Teil der
Informationen darstellt. Die allgemein als sinnvoll betrachteten
Ansätze zerfallen in zwei Kategorien: die Selektion und die
Abstraktion.
Die Selektion arbeitet nach dem Prinzip, aus einer großen Datenmenge
lediglich einzelne Teile herauszufiltern und nur diese anzuzeigen. D.h. alle
Daten, die einem gewissen Kriterium nicht genügen (z.B. Knotengrad,
Kantengewicht etc.), werden nicht betrachtet. Der resultierende Graph ist
also ein Teilgraph des ursprünglichen Graphen.
Bei der Abstraktion hingegen werden alle Daten in den Prozess
einbezogen. Resultat ist ein neuer Graph. Für die Repräsentation
der Ergebnisses des Prozesses durch einen Graphen gibt es verschiedene
Möglichkeiten. Eine sehr häufig eingesetzte Methode ist die der
Partitionierung. Dafür wird der Graph so in Teile zerlegt, dass diese
bezüglich eine bestimmte Bewertungsfunktion optimal gewählt sind.
Die einzelnen Teile werden dann als Knoten im neuen Graph verwendet.
Für eine ausführlichere Beschreibung zum Thema Partitionierung
siehe [Algorithmische Aspekte]. Ist man jedoch nicht nur an
einer einzigen Abstraktionsstufe interessiert bzw. reicht diese nicht aus,
so kann man das Verfahren auch rekursiv anwenden und kommt so zu einer
hierarchischen Repräsentation. Auf jeder Ebene steht ein Graph, dessen
Knoten wiederum für andere Graphen stehen, bis auf unterster Ebene
einzelne Teilgraphen des Ausgangsgraphen stehen, aus denen der gesamte Graph
zusammengesetzt werden kann. Dieses Prinzip ist in folgender
Abbildung dargestellt
(linke Seite 2-dimensional, rechte Seite 3-dimensional).
 Beispiel für eine hierarchische Zerteilung eines Graphen
Beispiel für eine hierarchische Zerteilung eines Graphen
Mit dieser hierarchischen Zergliederung eines Graphen gibt es nun neue
Möglichkeiten, die Graphdaten zu repräsentieren. Der Benutzer
kann nun ausgehend von der gröbsten Abstraktion einen Teil des
Graphen immer genauer betrachten (vertikales Navigieren). Ferner ist es
auch möglich, auf einer Ebene zwischen Abstraktionen für
verschiedene Teilausschnitte zu wechseln (horizontales Navigieren).
Zusammenfassung und weitere Fragestellungen
Für die Darstellung von großen Netzwerken existieren zahlreiche
Methoden zur Visualisierung. Dabei erweist sich der Ansatz einer
hierarchischen Aufteilung des Graphen als sehr sinnvoll. Für diese
Art der Darstellung sind einige Präsentationsalgorithmen entwickelt
worden, siehe beispielsweise [Ee96].
Hierbei werden zumeist die
Darstellungen für einen gegebenen Graphen berechnet und dann dem
Betrachter in geeigneter Form präsentiert. Für eine
Dynamisierung dieses Prozesses wurde bisher noch keine geeignete
Lösung gefunden, die ein wiederholtes Berechnen der kompletten
Aufteilung vermeidet. Es fehlen also noch Erkenntnisse, wie sich ein
Änderung des Graphen auf die Partitionierung auswirken.
Algorithmische Aspekte
Im Rest dieses Teilabschnitts werden nun einige Fragestellungen und Ergebnisse
zu weiter oben nur kurz angesprochenen Problemen und Algorithmen ausgeführt.
Eigenschaften von Graphklassen
Grapheigenschaften können das Ergebnis bzw. die Komplexität
eines Algorithmus entscheidend beeinflussen. Wie bereits gesehen, ist es aber
nicht immer möglich, diese Aussagen für einen Graphen vorab zu treffen.
Häufig greift man deshalb auf Modelle oder
Graphklassen zurück. Hierfür werden dann wesentlichen Eigenschaften erforscht
und möglichst genau eingegrenzt. Zwei wichtige Gruppen von Eigenschaften mit
entsprechenden Anwendungen seinen nur exemplarisch genannt:
- Weglängen - unter diese Kategorie fallen kürzeste und längste Pfade.
Dabei interessiert dieser Wert für spezielle Konstellationen von Quelle und Senke.
Es werden hierfür alle möglichen Paare und auch die Durchschnittswert
betrachtet. Häufig wird auch der Wert des Durchmessers von Graphen herangezogen.
Dieser leitet sich aus entsprechenden Weglängen ab.
Mit diesen Ergebnissen können Aussagen für viele Fragen
von Nachrichtenaustausch, wie Transportzeiten, Broadcastgeschwindigkeiten etc. erzielt
werden.
- Zusammenhang/Dichte - In dieser Gruppe werden Knoten- bzw.
Kantenzusammenhang sowie die Verteilung der Knotengrade betrachtet. Diese Informationen
sind wesentlich für die Analyse von Ausfallwahrscheinlichkeiten oder
Ausweichmöglichkeiten in Kommunikationsnetzen. Dies beinhaltet auch Untersuchungen
der Auswirkung von lokalen Modifikationen in allgemeinen Netzwerken.
Partitionieren
Im Bereich der Partitionierung, d.h. Aufteilung von Graphen, wurde bereits
viel Vorarbeit geleistet. Gerade im VLSI-Design sind mehrere Methoden
entwickelt worden [Len90]. Grundlegend
bei der Partitionierung ist die Bewertungsfunktion. Als Parameter stehen
dabei strukturelle Daten der Graphen (Knotengrade, Kanten- und
Knotenanzahlen etc.) sowie Bewertungen von Kanten und Knoten zur
Verfügung.
Zu den einfachsten Bewertungsfunktionen zählt die des Min-Cut, der
zählt, wieviel Kanten über den Schnitt gehen, bzw. wie groß
die Summe der entsprechenden Kantengewichte ist. Meist ist es jedoch
sinnvoll, die Forderungen nicht nur an die Größe des Schnitts zu
stellen, sondern auch die Größe der Komponenten zu
berücksichtigen. Neben der klassischen Forderung, dass die Komponenten
gleich groß sein sollen, kann man auch Schwankungen zulassen bzw. die
Größe der Komponenten mit in die Funktion aufnehmen. Eine
häufig verwendete Funktion ist der sogenannte Ratio-Cut [WC91, RS97]. Ab und an stößt man auf
leicht unterschiedlich Definitionen, aber im Wesentlichen wird der Quotient
aus der Größe des Cuts und dem Produkt der Größen der
Komponenten verwendet. Es nehmen also die Partitionen einen kleinen Wert an
(es wird in diesem Fall das Minimum gesucht), die einen geringen Cut bei
möglichst ausgewogenen Partitionsgrößen besitzen.
Unglücklicherweise führen jedoch diese Bewertungsfunktionen, die
auch eine Größenanforderung beinhalten, zu
NP-vollständigen Problemen
[GJ79]. Jene ohne dies Anforderung gibt es
effiziente Algorithmen, deren Lösungen für viele Graphen aufgrund
der ungleichen Größenverhältnisse der resultierenden
Partitionen jedoch nicht verwertbar sind. Um das Problem dennoch
algorithmisch bearbeiten zu können, wurden viele Methoden
vorgeschlagen. Einige Ansätze, um gute Partitionierungen erzielen, sind
im Folgenden aufgelistet:
- Move-Based - Dieser von Kernighan und Lin [KL70]
entwickelte und von Fiduccia und Mattheyses [FM82]
verbesserte Algorithmus zur Bipartitionierung verschiebt solange Knoten
über einen initialen Schnitt, bis keine Verbesserung der Bewertungsfunktion
mehr zu erreichen ist.
- Spektral - Mittels der Eigenwerte und zugehörigen Eigenvektoren der
Adjazenz- bzw. der Laplacian-Matrix des Graphen wird jedem Knoten ein Vektor
zugewiesen. Diese Vektoren, und somit die zugehörigen Knoten, werden dann geeignet
partitioniert [CSZ93].
- Random Walks - Durch den Einsatz von Random Walks wird für jeden Knoten/jedes
Knotenpaar ein Schätzwert bestimmt. Im Algorithmus von Hagen und Kahng ist dies ein
Schätzer
für die Anzahl der kurzen Kreise, in denen beide Knoten vorkommen. Aus diesem
Wert wird dann geschlossen, ob die Knoten in einer gemeinsamen Komponente liegen sollen
oder nicht.
- Zusammenhang - Ein iterativer Algorithmus von Garbers, Prömel und Steger fasst
Knotenpaare, die einen gewissen Zusammenhang haben, in Komponenten zusammen und ermitteln
so eine Partitionierung [GPS90].
Eigene Vorarbeiten
Entwicklung von Visualisierungstechniken
Im Rahmen von Diplomarbeiten wurden bereits Erfahrungen im Bereich
Visualisierung von Daten und Algorithmen gesammelt. Ein Schwerpunkt lag
hierbei auf der Visualisierung von Graphen und zugehörigen Algorithmen. Hier
seien drei Arbeiten exemplarisch genannt:
- In der Arbeit [Ern98] wurde ein Werkzeug
zur Visualisierung verteilter Graph-Algorithmen entwickelt.
Der Schwerpunkt der Graphvisualisierung liegt
hierbei in der Darstellung sehr großer benutzerdefinierter Graphen. Das System
bedient sich 2- und 3-dimensionaler Layouts und erlaubt dem Benutzer neben den
bereits erwähnten Zoom-Techniken auch virtuelle Kamerafahrten durch den
Graphen. Zudem sind Spring-Embedder-Algorithmen zur Auflösung von Clustern
implementiert.
- Zur Visualisierungen im Internet wurde in [Hol99]
eine JAVA Bibliothek erstellt, die eine Client-/Server gestützte Darstellung von
Graphalgorithmen ermöglicht. Mittels eines Tutorialsystems kann der Benutzer
Informationen und Beispielabläufe von Graphalgorithmen betrachten. Hierfür
wurde ein eigenes Editorapplet realisiert in dem der Benutzer lokale oder
Server-seitige Datenstrukturen laden, manipulieren und speichern kann. Dieser
Editor dient ferner dazu die Algorithmen zu visualisieren. Der Ablauf der
Algorithmen geschieht benutzergesteuert und kann mittels eingearbeiteter
Werkzeuge analysiert und mit anderen Testläufen verglichen werden. Neben
der Darstellung von Graphdaten kann das System auch andere Strukturen (Listen,
Priority-Queues etc.) nutzen und visualisieren.
- Erfahrungen zur Darstellung von hierarchischen Datenstrukturen wurden
in [Thi99] gesammelt. Ergebnis war eine Anwendung,
die es ermöglicht, Organisationstrukturen in einem Unternehmen als Organigramm
darzustellen. Hierbei können verschiedene Datensätze aus einer
Datenbank extrahiert und am Bildschirm angezeigt werden. Die Darstellung ist frei
parametrisierbar, so dass verschiedene, datenbankabhängig definierten Knoten- und
Kantentypen unterschiedliche Darstellungsformen zugewiesen werden können.
Erste Schritte bezüglich interessanter Fragestellungen
Als direkte Vorarbeiten zu diesem Projekt sind noch keine Veröffentlichungen
erschienen. Es wurden aber bereits erste Untersuchungen gestartet.
- Eigenschaften von Graphen (kürzeste Wege) - Der von Kleinberg
vorgestellte Ansatz eines dezentralen Algorithmus
[Kle00] für das
Transportproblem in Gittern mit zufälligen zusätzlichen
Kanten (siehe Kleinbergs Modell
für Small World Graphen) wurde auf ein anderes Modell
übertragen. Betrachtet wurde eine Mischung aus dem
Modell von Watts und Strogatz
und dem Modell von
Kleinberg. Die Struktur besteht aus einem Ring, wobei jeder Knoten
mit seinen d nächsten Nachbar verbunden ist. Ferner besitzt
jeder Knoten weiter Kanten, für die die Wahrscheinlichkeit analog
zu der von Kleinberg in Abhängigkeit des Knotenabstands und eines
festen Parameters α gewählt ist. Für diese Art von
Graph konnte gezeigt werden, dass das Transportproblem durch einen
dezentralen Algorithmus in erwarteter Zeit O((log
n)2) gelöst werden kann, falls der Wert α gleich
1 gesetzt wird. In allen anderen Fällen können lediglich
polynomielle Laufzeiten erzielt werden. Dieses Ergebnis sollte sich
analog auf andere Dimensionen übertragen lassen, wie Kleinberg es
ja bereits für 2 Dimensionen (Gitter) durchgeführt hat. Die
``optimale'' Belegung für den Wert α sollte hierbei der
Dimension entsprechen.
- Test für spektrales Clustering - Auch für das von Albert
und Barabasi vorgeschlagene
Modell für Small World
Graphen wurden Analysen durchgeführt. Aufbauend auf dem
spektralen Clusteralgorithmus von Chan, Schlag und Zien
[CSZ93] wurde die Struktur von
zufällig generierten Graphen der Klasse der power-law Graphen
untersucht. Hierbei konnten analoge Ergebnisse wie bei Broder et al
[BKM+00] abgelesen
werden. Ebenfalls tritt jeweils eine große
Zusammenhangskomponente auf, die einem stark zusammenhängenden
Graphen ähnelt, der an den Rändern immer mehr die Form von
Bäumen annehmen.
- Es wurde ein effizientes Verfahren
[Ern00] angegeben, mit dessen Hilfe
dichte Teilgraphen eines beliebigen, gewichteten oder ungewichteten
Graphen isoliert werden können. In einer Anwendung aus der
Bioinformatik dient das Verfahren dazu, die Strukturen eines aus
isolierten Cliques bestehenden, aber starkem Rauschen unterworfenen
Graphen zu rekonstruieren. Ziel hierbei ist das Clustern von
Genexpressionsprofilen. Die verwendeten Techniken beruhen auf der
spektralen Graphentheorie sowie der Störungstheorie.
Hanjo Täubig
Last modified: Thu Aug 29 13:29:37 CEST 2002